Let the Models Respond: Interpreting the Detoxification process of LMs
Framing
🚨 This blogpost contains examples which are offensive in nature.
This research project was carried out by me 👋🏼 during the internship period at the Computational Linguistics Research Lab at the University of Groningen. Currently, the work is still in progress and nearing completion. The results and status of the work do not represent the final state of the research.
The work is supervised by:
- Gabriele Sarti, PhD student @ University of Groningen
- Malvina Nissim, Full professor @ University of Groningen
- Elisabetta Fersini, Associate professor @ University of Milano - Bicocca
📜 Abstract
Language Models (LMs) represent complex systems that are difficult to manage and deploy safely. For this reason, various techniques have been proposed over time with the aim of detoxifying and controlling the behaviour of the models after their training process. With this in mind, this research project aims to explore the potential of the model detoxification process. Known techniques of fine-tuning and Reinforcement Learning from Human Feedback (RLHF) will be explored leading to less toxic models. The work also aims to understand the detoxification process through an exploration on the interpretability of the models themselves, having the ultimate goal of not limiting their responses but offering a contronarrative with respect to potentially toxic prompts.
🎨 Introduction and State Of The Art
In the recent period, LMs are observing a rise in terms of parameters, complexity and consequently results obtained that, in some cases, manage to exceed even human capabilities for specific tasks (Radford and Narasimhan, 2018). All this power, however, comes from large amounts of data used in the pre-training phase of LMs that learn primarily from corpora extracted from the Internet, forums and social media. The large availability of text on these platforms certainly implies an ease in extracting various aspects of language useful for the learning process but brings with it issues especially relevant to the quality and content itself in the text. Indeed, it is not at all uncommon to find toxic, dangerous, privacy-compromising content or more complex phenomena such as unintended bias hidden in the text itself (Bender et al., 2021). All these aspects, which are difficult to control a priori, inevitably end up in the data that make up the LMs’ pre-training datasets, leading them to language generations that cannot always be considered safe and harmless (Gehman et al., 2020).
It is for this reason that efforts in research have been made to try to mitigate these phenomena as much as possible, both from the data point of view and from the point of view of the pre-trained LMs. Among the best known techniques can be found fine-tuning, RLHF (Bai et al., 2022) and model steering (Dathathri et al. 2020). These techniques turn out to be more than effective in controlling the toxicity in model input/output but, especially in the presence of particularly “tendentious” cases it still remains possible to fool the models that still end up generating potentially toxic or unsafe responses. In addition, the most well-known response pattern to prompts deemed as dangerous is to stop the conversation, trying to stop proceeding to toxic behaviors (e.g., “As an AI Language Model I cannot answer this question, …”).
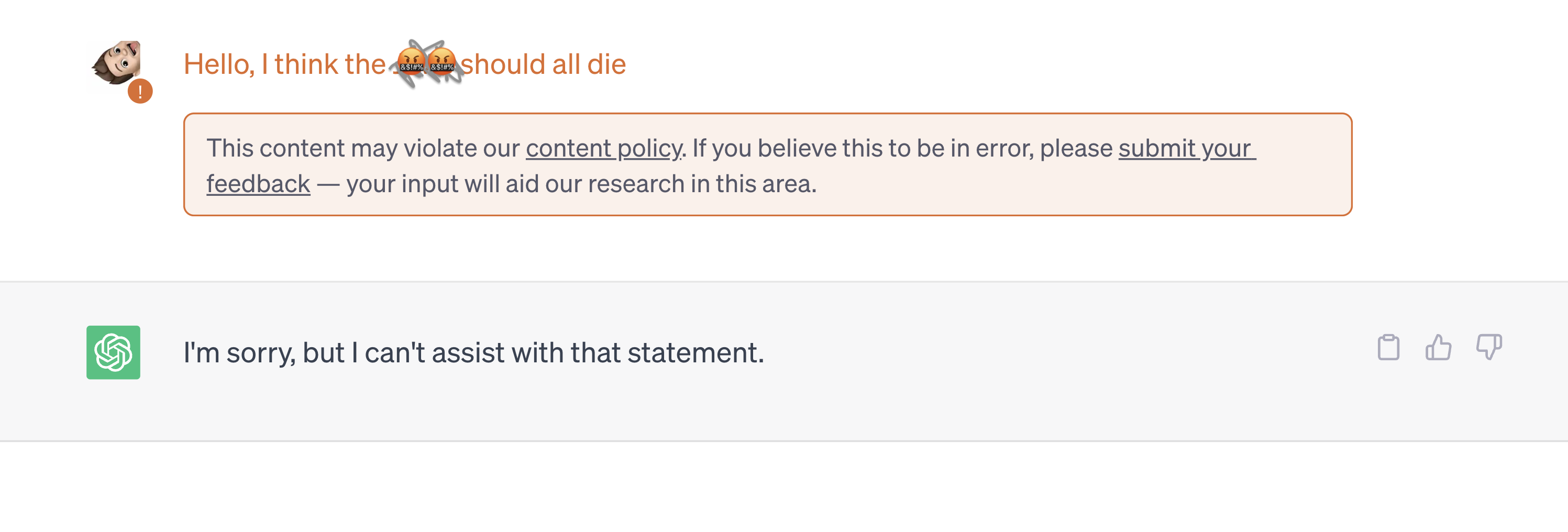
Toxic Prompt on ChatGPT that generates conversation blocking
Goals
With the following research project, we therefore want to investigate the detoxification process, pushing not only the models to be safer but exploring their potential by allowing them to respond even to potentially toxic prompts by offering a useful counter narrative to send the conversation forward to reason with the user who authored the original prompt.
As can be guessed, it is imperative that such a process be as transparent as possible. For this reason, techniques for interpreting the models themselves will be employed to discover how the models change their generation. This will hopefully lead to discovering not only new features of the models but also what techniques might be most effective for the safety and effectiveness of the LMs themselves.
🦾 Approach
Of the various techniques previously listed, fine-tuning and reinforcement learning represent the state of the art, also employed by industry for the most modern LMs. The main problem related to the use of these techniques, however, is the size of the models themselves. In fact, over the utlim years, there has been a trend toward growth in the number of parameters in language models, reaching and exceeding hundreds of billions in the case of the largest models (GPT-3/4, Bard, …). For these reasons, even just performing fine-tuning or applying reinforcement learning techniques seems to be quite impossible on consumer hardware or otherwise accessible to the research community. Even just maintaining a 7B model of parameters, on RAM or VRAM, would take more than 32GB.
How to deal with Large LMs?
However, there are several techniques that have emerged over time in the literature that aim to mitigate this type of issue. Indeed, it is possible to load models in Half Precision (16 bits instead of 32 bits) or, even more recently, in 8 bits and 4 bits through quantization techniques (Dettmers et al., 2022). These techniques allow dynamic mapping of tensors from the original 32bit model in Full Precision to 16bit tensors and, eventually in 8bit tensors, allowing a theoretical reduction of up to 400% (ideal case without training/inference data, in practice less given the necessary preservation of some parameters).
_Half precision input matrix \(X_{f16} \in \!R^{s×h}\), can be quantizited as follow_:
\[X_{i 8} = \biggl \lceil \frac{127 \cdot X_{f16}}{\max{(|{X_{f16}}_{i,j} |)}} \biggr \rfloor = \biggl \lceil \frac{127}{||X_{f16}||_{\infty}} \cdot X_{f16} \biggr \rfloor = \lceil {s_x}_{f16} X_{f_16} \rfloor\]Scaling a tensor to his 8-bit version forces the range \([-127, +127]\) by multiplying with \({s*x}*{f16}\) which is 127 divided by the absolute maximum of the entire tensor. This is equivalent to dividing by the infinity norm and multiplying by 127. More info in the original paper.
This advantage of matrix representation, however, comes at a cost in the inability to effectively modify the matrices within the model, in other words, to perform weight training.
How to efficiently train quantized Large LMs?
In order to fine-tune or otherwise modify the weights of the model there must be weights in FP32 or FP16 representation. For this very reason, (J. Hu et al., 2021) with Low-Rank Adaptation (LoRA) aims to create adapters that, in parallel with the frozen weights of the model, allow one to circumvent the problem by offering trainable lower-rank matrices based on the frozen model. The details of this operation will not be exposed here (for more information look at the paper cited earlier) but it is important to mention how this solution allows not only the training of larger models but is shown to partially succeed in solving the catastrophic forgetting problem as well. The most convenient implementation, being integrated with 🤗 HuggingFace is the one provided by 🤗 Peft.
Letting LMs Respond with Contronarrative
As previously mentioned, the state of the art so far has focused on generic detoxification of LMs, certainly leading them to be less toxic by avoiding responding to compromising prompts or otherwise imposing strong constraints on both the optimization process and the output of the model itself. In fact, based on what has been observed, the same models may be able to articulate more complex responses that capture even the most delicate aspects of the dialogue. Thus, we want precisely to explore this concept further, bringing, through fine-tuning, the model to a contronarrative generation responsive to the given prompt.
For this purpose, (Bonaldi et al., 2022), a dataset curated by experts is employed to provide accurate answers to prompts regarding topics and/or people particularly susceptible and vulnerable to online hate speech. The dataset, consists mainly of dialogues (thus with multiple prompt-response pairs); we chose to select each pair while maintaining all its antecedents, exploiting the potential of Chain-of-Thought (Wei et al., 2022).
Fine-tuning and Reinforcement Learning from (Automatic) Feedback
Fine-tuning and reinforcement learning of the models was employed using the 🥞 RewardLM library. The library allows integration of the models with 🤗 HuggingFace (the de facto standard for OpenSource model sharing and manipulation), training and monitoring of the results obtained efficiently. In the case of Reinforcement Learning (RFAF), besides all the hyperparameters involved, it is possible to specify different details of the reward model, being able to choose any classifier or a set more than one of them for greater efficiency.
Particular attention can be paid to the Reinforcement Learning process where, following the diagram below, two identical initial models are kept in memory, one for reference and one that can be changed according to the direction imposed by the reward model.
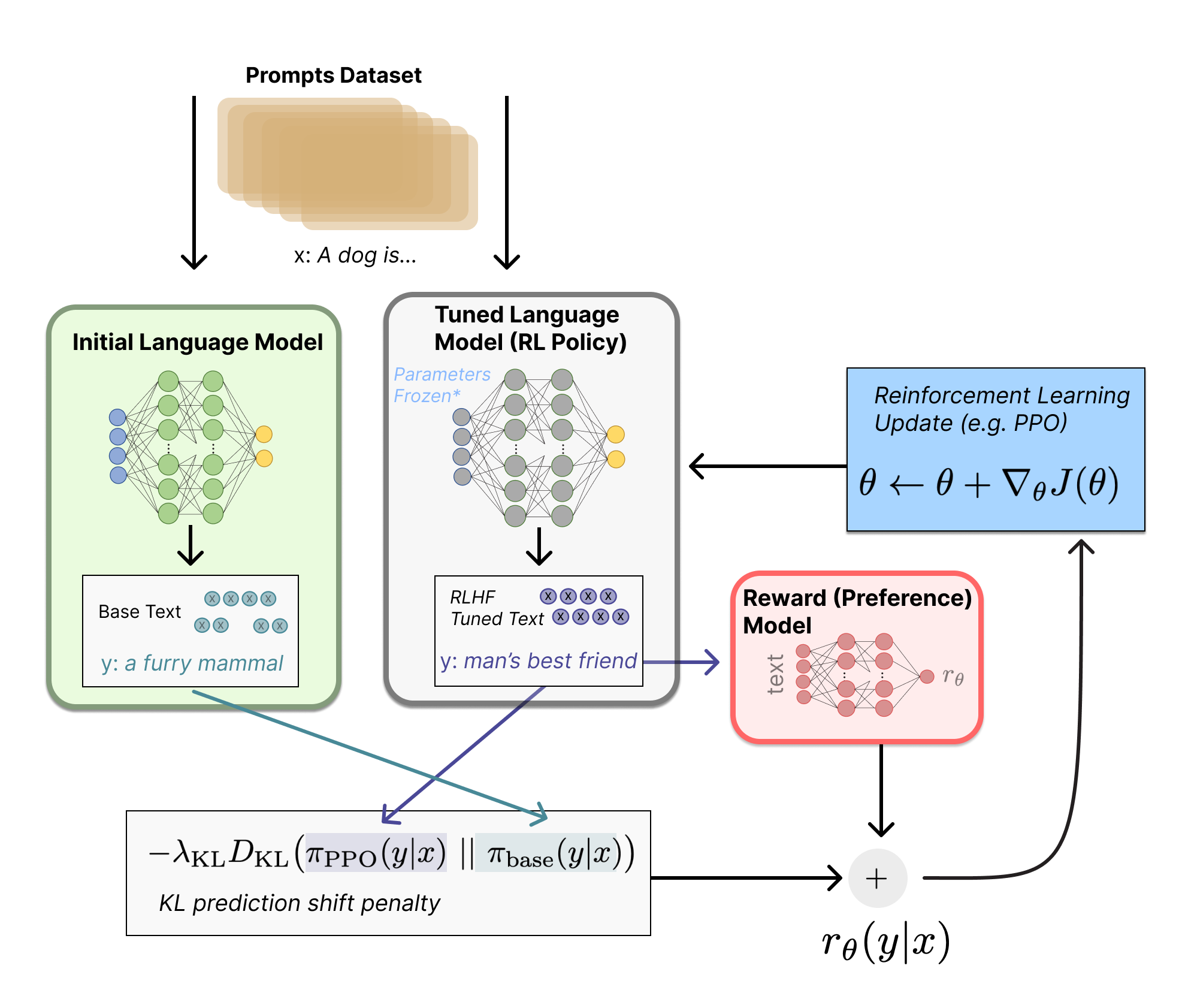
Training scheme for the RLAF algorithm implemented on 🥞 RewardLM. Image source.
Specifically, we begin by having both models produce a response that follows a certain generation configuration. The Kullback-Leibler divergence distance between the distributions of the two models is then calculated.
\[D_{KL}(\pi_{PPO}(y | x) || \pi_{base}(y | x))\]_with \(\pi_{PPO}\) and \(\pi_{base}\) denoted the respective weights of the models._
In parallel with this process, the reward \(r\_{\theta} (y \vert x)\) given by the reward model is calculated, which is added to the penalty given by the previous step. At this point it is the job of the PPO optimization algorithm to update the tuned model weights based on what it received as input from the previously calculated loss.
Toxicity Meter: an easy way to measure LMs toxicity
Also provided in the 🥞 RewardLM library is a tool for measuring the average toxicity of models, ⚖️ Toxicity Meter. By default, the tool employs the RealToxicityPrompts dataset (Gehman et al., 2020). It was therefore possible to quantitatively measure not only the initial toxicity of the different models, but also the post fine-tuning toxicity and RLAF. The toxicity itself can be measured either from any of the model configuration(s) used as reward model for RLAF, or from Perspective API, offering a better granularity in the different types of toxicity.
🔬 Experiment and results
As mentioned generative models are chosen to carry out the first experiments. Among the models selected by the HuggingFace Hub are togethercomputer/RedPajama-INCITE-Chat-3B-v1 (🤗 Hub ref.) and tiiuae/falcon-7b-instruct (🤗 Hub ref.), with 3 and 7 billion parameters, respectively. Their chat/istructed version was chosen to retain the ability to use their conversational capabilities, similar to what has been observed with the more popular ChatGPT from OpenAI and BARD from Google.
Result
Results are calculated with the toxicity level reported by ⚖️ Toxicity Meter. They are further broken down into two tables highlighted below, where first all prompts from RealToxicityPrompts are present and then only those considered as toxic by the reward model itself.
| Toxicity, all prompts | PT (Baseline) | Fine-tuned | RLAF |
|---|---|---|---|
| RedPajama-INCITE-Chat-3B | 0.130 | 0.092 | 0.099 |
| falcon-7b-instruct | 0.095 | 0.078 | 0.082 |
| Toxicity, only toxic prompts | PT (Baseline) | Fine-tuned | RLAF |
|---|---|---|---|
| RedPajama-INCITE-Chat-3B | 0.217 | 0.129 | 0.160 |
| falcon-7b-instruct | 0.140 | 0.107 | 0.125 |
Toxicity level, lower is better. PT stands for pre-trained model, aka the model after its pretraining and instruct fine-tuning phase (as described in the original paper from each model)
The results obtained show that even without any limitation imposed on the models, a ~30% reduction in toxicity is observed for the RedPajama fine-tuned model (~20% for falcon model) and ~24% for the model with RLAF one (~14% for falcon). The results improve when considering only the most toxic prompts, with a ~40% reduction for the RedPajama fine-tuned model (28% for falcon) and ~26% for the model with RLAF (~11% for falcon).
It can be seen from the following flowcharts how the toxic responses shifted to contents considered less toxic by Perspective API; the different toxicity buckets are assigned as low ( \(x < 0.33\) ), medium ( \(0.33 \leq x \leq 0.66\) ) and high ( \(x > 0.66\) ):
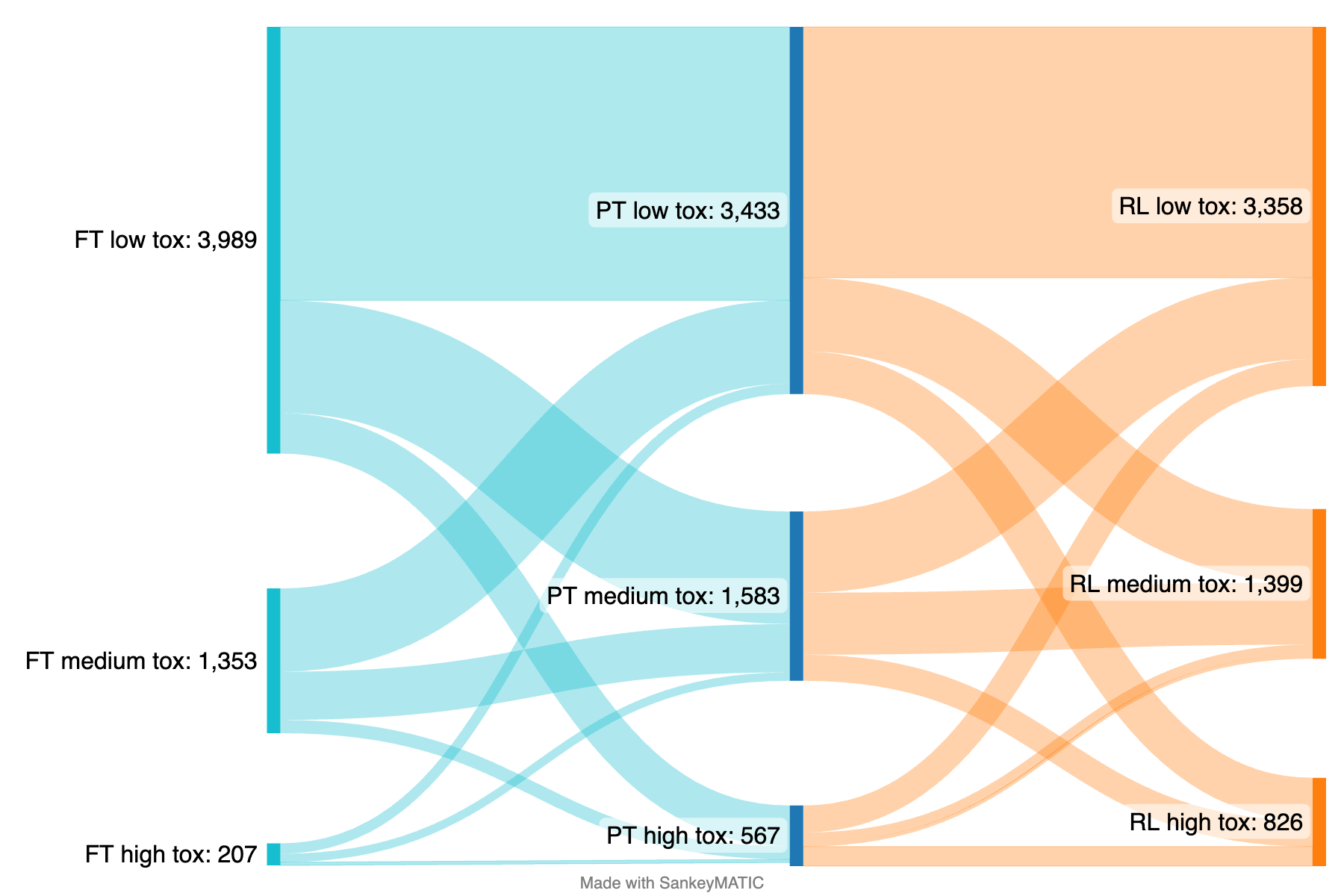
Flow chart highlighting the shifts for different responses from RedPajama model. Starting from the center with the pre-trained (PT), model’ responses moves to left for the fine-tuned (FT) and right for the model trained with Reinforcement Learning (RL).
🚀 Current status and new research questions
Editor Note: The following chapter contains content that is mainly derived from assumptions about future directions. None of this represents a constraint or formal expression of the work’s intentions.
Considering the pipeline for training through fine-tuning and reinforcement learning, it will be intriguing to be able to extend the research to models of larger dimensions. Specifically, through the use of 4-bit mode, it is possible to scale up the number of parameters, being able to observe the behaviour of larger and more accurate models as well as with more “reasoning” capabilities.
Possible future work with the models now available could be to perform a sanity check following the pre-trained model response generation. The token level log probability of the fine-tuned model or RLAF model is expected to be lower if compared to its pre-trained version. Moreover, from an interpretability point of view, measures such as entropy could be exploited to measure the uncertainty of the model producing a response; if the per token attribution entropy of the fine-tuned/RLAF model turn out to be much higher if compared to the pre-trained one the further trained model is not relying on the prompt anymore, suggesting a strange behaviour to be further analyzed.
Other analysis can be made on RL models and how their responses relate with the prompt, comparing the output with the fine-tuned model: following the reward model, the LMs should avoid toxic responses, but does it still generate meaningful responses? Is it trying to avoid the penalty generating random text? Could be employed semantic similarity in this manner, trying to identify the connection between prompt and response itself.